
You know, for search
As soon as you start having a good amount of data, browsing them is not anymore a solution and you need a search engine. It happened to us some time ago at Scoop.it. We are pretty happy with what we put in place almost 2 years ago. Let’s revisit the story.
Which one ?
So we need a search engine. Then, which technology to use ?
At Scoop.it, some of us engineers have some nice experience with Apache Lucene so we wanted to work with it again. But this time, rather than just using the Lucene library, and managing ourself the replication of the index in the cluster, we wanted something more plug and play. And we wanted something opensource, because we often want to understand the internal to better understand the behavior of a software, and nothing can better document internals than code. And opensource because no software is perfect and we are not afraid to get our hands dirty to fix it. Another point we take into account is the community around the software. An active community around a software always means that it is actually used in a wide variety of use cases and it is likely that someone else with the same use case as our has already hit and fixed bugs.

We know Apache Solr, we played a little bit with it, it is nicely extensible, but we didn’t like the way the replication work. In the standard version of Solr, the replication is quite smart, rsync and Lucene’s management of its index files fit well together. But it relies on some shell scripts, this makes things not well integrated. What about the clustering setup ? One master for writes and slaves for reads ? What about single point of failure ? We didn’t try to answer these questions since we were not confident on the replication technology. If you know about Solr too, you probably want to poke me: « Hey, there’s Solr Cloud, the distributed version of Solr ! » Well, 2 years ago it was far from being ready. And knowing that the distributed architecture is based on Zookeeper, it was a little bit more difficult to trust its stability.
The right one
Then a friend told us to have a look at Elasticsearch.

The website changed since then, but the catch phrase in the website starts with "You know, for Search". We like the spirit ! And the nice keywords were there: "painless setup", "always available", "scale to hundreds", "real-time search" and "built for the cloud" for the final touch.
So we looked closer, we tested it. We didn’t test it scalabilty per se, but since there is a nice activity on the mailing lists, and some are reporting quite large use cases, we were confident. We love the API, it feels like the Lucene API on HTTP/Json. We also do love the easy setup of a cluster, it is elastic for real. Elasticsearch still seemed to be a young project, at that time the backward compatibility was not kept between minor releases. We did faced some bugs, but as it is opensource, it was quite easy to patch and fix the code. We obviously contributed back, and the patches were quickly integrated into the mainstream. As a result, we had a working version of the search in two weeks only, search results layouting included.
After that wonderful bootstrap, then started the real work about setting up the search engine. I have worked several times with the Lucene library, but I always spent most of my time doing code plumbing than making the search engine work as expected. By that I mean make the search engine work so that when you search something, you find <i>good</i> results, and the good results <i>first</i>. It is all about the tuning of the boost on the queries, the boost on the documents and so on. Thanks to the very easy setup of elasticsearch, I could quickly start tweaking the internals of Lucene. I’ll write a dedicated post about it.
After that long journey, we finally got a wonderful search engine. Go check it out, it’s there: http://www.scoop.it/search
Oups…

These two years of Elasticsearch in production was not peaceful trip though. As I mentioned earlier it is still a young project. The first version deployed was a 0.16 so it was especially young at that time.
From time to time, for some unknown reason, the cluster of two nodes would split itself into two clusters. Those times you love resilient technologies: even if it goes wrong, it still basically works. Probably there were some inconsistencies due to the split brain. To avoid the split brain situation, we could have used a configuration in Elasticsearch (see <code>gateway.recover_after_nodes</code>) which is making it start only if it sees a minimum of other node; set this config to N/2+1 (N being the number total of nodes), and you’re sure to not have split brains. But in our case, with two nodes, it would mean that if one node goes down, the search would be unavailable. Having the search being down is far worst for us than have some inconsistencies, so we just implemented some kind of read repair for the worst inconsistencies (deleted topic or privacy issues). And at the end, if a split happens, just a reboot of one of the node, and everything could get back to "green".
But a few times things went particularly wrong. For some other unknown reason, one of the node would start snapshoting its index every minute. And we got notified by some alarms raised due to the disks being full. And to make things worst, there were a bug where we would loose data. Thanks to the replication, we would just shut down the haywire node, wipe out is data, and make it bootstrap again with the data from the healthy one.
Keep reading, Murphy’s law in action, we’re not there yet.
One time one node would fill the disk whereas the other would have a shard which wouldn’t "initialize" because it was found corrupted. So we lost data. We were good to reindex everything. And at that time, the elasticsearch nodes didn’t had their dedicated machines with SSDs; it took almost one month to get things back to normal. It could has gone even worst, as during that period we did managed to still run with 4 out of 5 shards and one running node. New stuff wouldn’t show up in the search and 1/5th of the data would be there at all, but the search would still appear as basically working.
Cherry on the cake, I happened around the 20th of December afternoon, few hours before going on vacation for Christmas!
Here I find elasticsearch way too quiet in its log about its internals. I understand that there’s no documentation of the internals of Elasticsearch, because it is a PITA to maintain (when working on internals, we don’t write proses, just want to hack, hack and hack !). At least it could tell us what it is doing from time to time, especially when shards are automagically moving around. When we got real troubles, the only log we had were that the shards were failing to be initialized; not a word about why snapshoting was happening. It made bug reporting useless, so we would just restart and pray. And probably one time my prayers were not good enough, Santa Claus was probably angry because I started to have doubt on his existence, shame on me!
Deep breath

After these trouble times, the elasticsearch nodes got their own hardwares, with SSDs and more RAM, we upgraded the elasticsearch to get the clustering fixed. And we didn’t have any trouble since.
Some weeks ago, we saw some increased activity on the garbage collector. As I will explain in another post, our tweaks on search heavily use the field cache for querying. So it was a call for more capacity. « We need more RAM ! » we often like to yell as soon as we have capacity issues. But this was awesomely fixed by upgrading to elasticsearch 0.90, which contains a great memory usage optimisation. You can see the effect on the following graph, at the beginning of June.
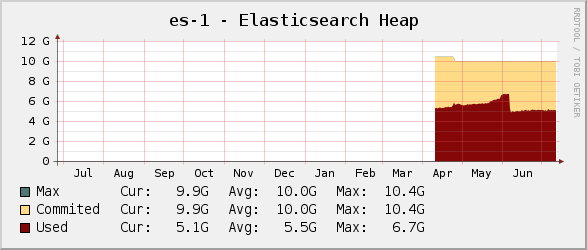
At the end of the day
All things considered, we are quite happy with Elasticsearch. It is still a young project, its numbering is speaking for itself, it is not yet a stable 1.0. But it’s not that far. There could be some trouble here and there, but as it is quite resilient, I wouldn’t expect data lost anymore. We’re still missing some easy index backup strategy, but I have read that this is planned and coming soon.
Definitively, Shay has wrote an awesome piece of software, and I am glad some great talents has joined him.